MySQL索引、视图、三大范式的学习
1 索引
1.1 介绍
- 索引类似书的目录,通过目录可以快速的找到对应的资源
- 索引添加在某个字段或某些字段
- 主键和具有unique约束的字段会自动添加索引
- 模糊查询会导致索引失效
- 在数据库方面,查询一张表有两种检索方式:
- (1)全表扫描
- (2)根据索引检索(效率高)
- 优点:索引通过缩小扫描范围,提高检索效率
- 缺点:一旦数据发生修改,索引需要重新排序,进行维护;如果数据经常进行DML操作,就不适合使用索引
1.2 使用场景
- (1)数据量庞大
- (2)索引字段很少DML操作
- (3)该字段经常出现在where子句中
1.3 使用
1 | # 创建索引 |
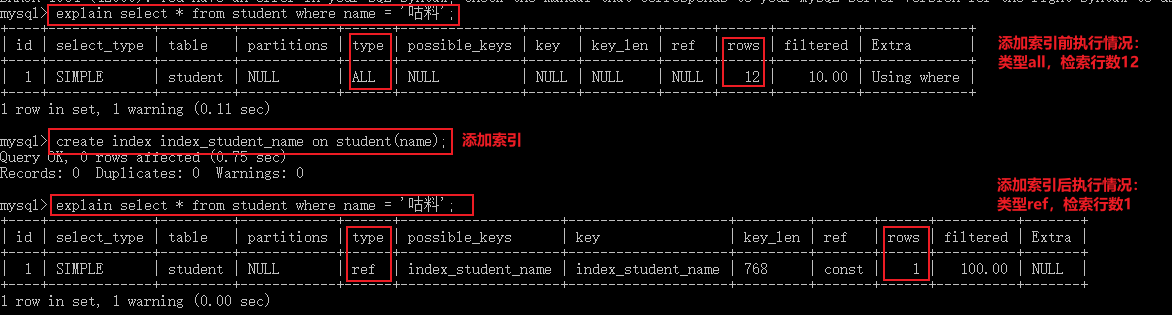
1.4 索引底层原理
- 索引底层采用的数据结构为B + Tree
- 在创建索引的时候,会自动对该字段的数据进行排序和分区。所以使用索引会同一个个区域寻找,定位该区域后,在该区寻找数据。
- 索引会直接携带数据的物理地址,当通过索引找到对应的数据时,会直接通过物理地址取出数据,速度快
1.5 索引分类
- (1)单一索引:给单个字段添加索引
- (2)复合索引:给多个字段联合起来添加1个索引
- (3)主键索引:主键会自动创建索引
- (4)唯一索引:unique约束的字段会自动创建索引
2 视图
2.1 介绍
- 用不同的角度看待表,即同一张表,可以截取部分字段,作为视图
- 对视图的CRUD操作,会影响到原表的数据
- 作用:截取原表的部分字段,提供给其他人进行操作,能对数据原表起到保密作用。
- 在面对一些隐秘性比较高的系统,一般DBA只提供视图用来进行操作,不提供原表
2.2 使用
1 | # 创建视图(类似表的复制) |
3 DBA命令
1 | # 导出数据库/表(导完后该数据库/表会删除) |
4 数据库设计三范式
4.1 设计范式
- 按照范式设计的表不会出现数据冗余
4.2介绍
- 第一范式:任何一张表都应该有主键,每个字段的原子性不能再分
- 第二范式:建立在第一范式的基础上,所有非主键字段完全依赖主键,不能产生部分依赖

- 学生姓名只依赖于学生编号,并不依赖于教师编号,不满足第二范式
- 解决方法:创建学生表,教师表,关系表三张表来处理多对多关系
- 第三范式:建立在第二范式的基础之上,所有非主键字段直接依赖主键,不能产生传递依赖

- 班级名称依赖于班级编号,班级标号依赖于学生编号,产生传递依赖
- 解决方法:创建一个班级表,用来保存班级名称。原表只有班级编号。解决一对多关系
- 口诀:一对多,两张表,多的加外键;多对多,三张表,关系表加外键;
- 在实际开发中,以满足客户的需求为主,有的时候会拿冗余度换区执行速度。一张表的执行速度,永远大于两张表
4.3 一对一设计
- 举例:用户信息一般分为两部分,用户登录信息和用户详细信息,用户登录信息系只保留用户名和密码,用户详细信息保留用户的其他信息
- (1)主键共享
- 用户详细信息表的id,即是主键,也是外键。晚间关联用户登录表的id

- (2)添加额外外键(一对多设计)
- 用户详细信息表额外字段名关联用户登录表id,约束为外键和唯一约束
