赫夫曼树延伸的赫夫曼编码的实现,以及压缩与解压的应用
1 赫夫曼编码
1.1 介绍
- 赫夫曼编码(Huffman Coding),又称哈夫曼编码、霍夫曼编码,是一种编码方式,属于一种程序算法
- 赫夫曼编码是赫夫曼树在电讯通信中的经典应用之一
- 赫夫曼编码广泛地应用于数据文件压缩,其**压缩率通常在20%~90%**之间
- 赫夫曼编码是可变字长编码(VLC) 的一种。Hufffman与1952年提出一种变法方法,称之为最佳编码
1.2 其他编码介绍
- (1)定长编码:一个文本,例
hello world,二进制编码是固定的(通过Ascii码,再转成2进制)
- (2)可变长编码:统计一个文本的中字符出现的次数,例
hello world,l:3 o:2 h:1 e:1 r:1 d:1 :1,按照赫夫曼树的思想(次数越大,越靠前),进行自定义二进制编码:l:0, o:1, h:10, e:11, r:100, d:101, :110来进行压缩,减少二进制编码占的空间
- (3)前缀编码:每个字符的编码都只能有一个,不能重复,具有唯一性。例:二进制字符
101001,有可能1或10或101是一个字符,出现匹配多义性,就不属于前缀编码
1.3 实现原理
- (1)以字符
hello world字符为例
- (2)跟可变长编码一样,统计各字符出现的次数
l:3 o:2 h:1 e:1 r:1 d:1 :1
- (3)以次数作为权重,以字符作为数据,来构建一个赫夫曼树
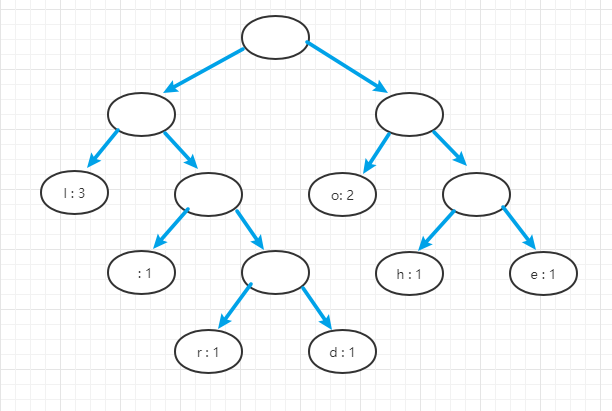
- (4)以左岔路为0,右岔路为1,对赫夫曼树进行编码,进而获得每个字符对应二进制编码(前缀编码)
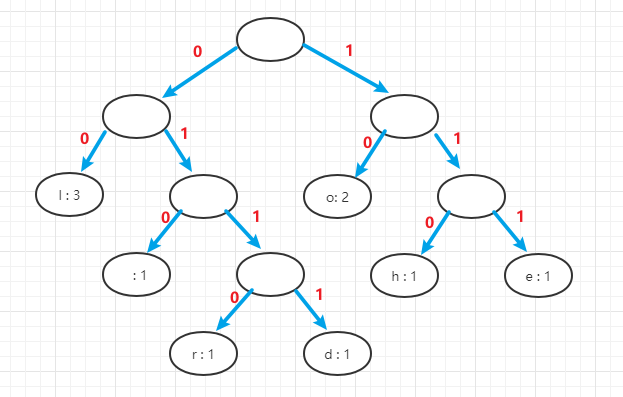
- 注意 :当一个赫夫曼树中出现多个权值相同的节点,根据排序算法的不同,有可能导致赫夫曼树的形状不同,进而导致赫夫曼编码不同,但是因为满足最小wpl,所以最终二进制编码的长度还是一样,不会发生改变
1.4 代码实现
- 前提 : 赫夫曼编码涉及赫夫曼树的知识,没有了解的,可以翻之前的文章进行了解,涉及赫夫曼树的代码不再过多注释解释
- (1)代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133public class HuffmanTree {
//子类 --- 节点
private class Node implements Comparable<Node>{
public int weight;
public Character c;
public Node left;
public Node right;
public Node(int weight, Character c) {
this.weight = weight;
this.c = c;
}
public Node(int weight, Character c, Node left, Node right) {
this(weight, c);
this.left = left;
this.right = right;
}
public int compareTo(Node o) {
return weight - o.weight;
}
public String toString() {
return "Node[weight = " + weight + ", char = " + c + ']';
}
}
//--------------------------------------------------------------------------------------
private Node root; //根节点
public HuffmanTree(char[] arr) {
createTree(arr);
}
/**
* 创建赫夫曼树
* @param arr 字符数组
*/
private void createTree(char[] arr) {
List<Node> nodes = toNodeList(arr);
while (nodes.size() > 1) {
Collections.sort(nodes);
Node left = nodes.remove(0);
Node right = nodes.remove(0);
Node parent = new Node(left.weight + right.weight, null, left, right);
nodes.add(parent);
}
root = nodes.get(0);
}
/**
* 将char数组转成List<Node>
* @param arr 字符数组
* @return List<Node>
*/
private List<Node> toNodeList(char[] arr) {
Map<Character, Integer> counts = new HashMap<>(); //字符统计集合(key为字符,value为个数)
//统计字符集合
Integer count;
for (char c : arr) {
//向Map查询该字符(不存在为null,存在则返回其Integer值)
count = counts.get(c);
if (count == null) {
counts.put(c, 1);
}else {
counts.put(c, count+1);
}
}
//读取Map,并封装为List<Node>集合
List<Node> nodes = new ArrayList<>();
for (Map.Entry<Character, Integer> entry : counts.entrySet()) {
nodes.add(new Node(entry.getValue(), entry.getKey()));
}
return nodes;
}
/**
* 获取哈夫曼编码
* @return Map<Character, String>
*/
public Map<Character, String> getHuffmanCode() {
if (root == null) {
System.out.println("树为空!");
return null;
}
Map<Character, String> huffmanCodes = new HashMap<>(); //赫夫曼编码集合
StringBuilder route = new StringBuilder(); //路径记录
//递归获取赫夫曼编码,并记录在Map结合中
getCode(huffmanCodes, root, route, "");
return huffmanCodes;
}
/**
* 递归获取赫夫曼编码
* @param huffmanCodes 赫夫曼编码结合
* @param node 节点
* @param route 路径
* @param direction 方向(0为左,1为右)
*/
private void getCode(Map<Character, String> huffmanCodes, Node node, StringBuilder route, String direction) {
StringBuilder newRoute = new StringBuilder(route); //创建新StringBuilder,避免影响传入的数据(避免影响回溯)
newRoute.append(direction); //拼接路径
if(node != null) {
//判断是否叶子节点
if (node.c == null) {
//向左递归
if (node.left != null) {
getCode(huffmanCodes, node.left, newRoute, "0");
}
//向右递归
if (node.right != null) {
getCode(huffmanCodes, node.right, newRoute, "1");
}
}else {
//是叶子节点,则记录该字节,以及路径(编码)
huffmanCodes.put(node.c, newRoute.toString());
}
}
}
}
- (2)测试
1
2
3
4
5
6
7
8
9
10
public void huffmanTreeTest() {
//获取赫夫曼树
char[] chars = "hello world".toCharArray();
HuffmanTree huffmanTree = new HuffmanTree(chars);
//获取赫夫曼编码表
Map<Character, String> huffmanCode = huffmanTree.getHuffmanCode();
System.out.println(huffmanCode);
}
2 字符串压缩与解压
2.1 补码&反码&原码
- 反码 = 补码 - 1
- 原码 = 反码 除了符号位(第一个数,0为正,1为负),其余都取反
2.2 介绍
- 赫夫曼编码,对原数据的编码就行改变,实现对数据进行压缩。压缩后的数据查询赫夫曼编码表,对数据进行解压,还原数据
2.3 代码实现
- (1)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133public class HuffmanCode {
private char[] chars; //原字符串的字符数组
private Map<Character, String> huffmanCodeTable; //赫夫曼编码表
private int lastLen; //数组最后的bit长度
//构造器(处理字符串,并生赫夫曼编码表)
public HuffmanCode(String str) {
this.chars = str.toCharArray();
huffmanCodeTable = new HuffmanTree(this.chars).getHuffmanCode();
}
/**
* 压缩字符串(编码)
* @return char[]
*/
public char[] strZip() {
//将字符数组转成对应赫夫曼编码的二进制bit形式字符串
StringBuilder code = new StringBuilder();
for (char c : chars) {
code.append(huffmanCodeTable.get(c));
}
//将bit形式字符串转成char数组(8位 = 1字节 = 1 char)
//计算字节数组长度
int len;
if (code.length() % 8 == 0) {
len = code.length() / 8; //是8的倍数,长度=除数
}else {
len = code.length() / 8 + 1; //非8的倍数,长度=除数+1(除法会向下取整)
}
char[] huffmanCodeChars = new char[len];
//将字符串转字节数组
int index = 0;
while (index < len) {
//计算截取位置(8位长度)
int start = index * 8;
int end = start + 8;
//判断截取长度是否超出,超出则截取剩余的
String subCode;
if (end > code.length()) {
subCode = code.substring(start);
}else {
subCode = code.substring(start, end);
}
//将2进制bit转成10进制int,强转为char
huffmanCodeChars[index] = (char) Integer.parseInt(subCode, 2);
//记录最后一个元素的长度,方便解压
if(index == len-1) {
lastLen = subCode.length();
}
//index自增
index ++;
}
return huffmanCodeChars;
}
/**
* 解压数据(解码)
* @param huffmanCodeChars 压缩后字符数组
* @return String
*/
public String strUnzip(char[] huffmanCodeChars) {
//将赫夫曼字符数组转成2进制bit字符串
String bitStr = charsToBitString(huffmanCodeChars);
//反转赫夫曼编码表(bit为key,char为value)
Map<String, Character> alterHuffmanCode = new HashMap<>();
for (Map.Entry<Character, String> entry : huffmanCodeTable.entrySet()) {
alterHuffmanCode.put(entry.getValue(), entry.getKey());
}
int index = 0; //下标
StringBuilder metaStr = new StringBuilder(); //原字符串
String tempStr = ""; //中间变量
//遍历字符串
while (index < bitStr.length()) {
tempStr += bitStr.charAt(index);
//匹配反转赫夫曼编码表
if (alterHuffmanCode.get(tempStr) != null) {
metaStr.append(alterHuffmanCode.get(tempStr)); //将识别的字符加入原字符串
tempStr = ""; //清空中间变量
}
//index自增
index ++;
}
return metaStr.toString();
}
/**
* 将char数组转为bit类型字符串
* @param huffmanCodeChars char数组
* @return String
*/
private String charsToBitString(char[] huffmanCodeChars) {
int n = huffmanCodeChars.length; //数组长度
int index = 0; //数组下标
int temp; //中间变量,存储字符
StringBuilder bitStr = new StringBuilder(); //二进制bit字符串
//遍历数组
for (char c : huffmanCodeChars) {
temp = c;
//对数据进行补位
//256的二进制为1 0000 0000,如果当前字符的二进制为正数,前面的0会被省略,需要进行补位
temp |= 256;
//判断是否最后一位,最后一位的长度不一定是8位数
String tempStr = Integer.toBinaryString(temp);
if (index == n-1) {
bitStr.append(tempStr.substring(tempStr.length() - lastLen)); //最后一位截取指定长度
}else {
bitStr.append(tempStr.substring(tempStr.length() - 8)); //其余截取后八位
}
}
return bitStr.toString();
}
}
- (2)测试
1
2
3
4
5
6
7
8
9
10
11
12
13
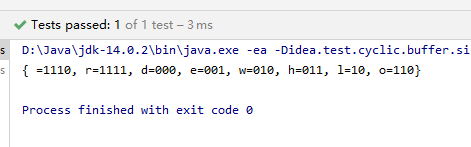
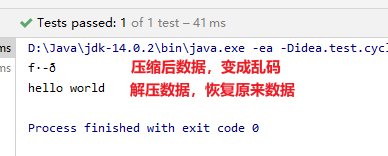
public void huffmanCodingTest() {
String str = "hello world"; //原数据
HuffmanCode huffmanCode = new HuffmanCode(str);
//压缩数据
char[] chars = huffmanCode.strZip();
System.out.println(chars);
//解压数据
String s = huffmanCode.strUnzip(chars);
System.out.println(s);
}
3 文件压缩与解压
3.1 介绍
- 文件的压缩与解压与字符串的压缩与解压差别不大,因为文件一般都是读取为byte[],所以我们创建赫夫曼树,以及创建赫夫曼编码表时,都是用byte[]数组存储,其他差别不大
3.2 代码
- (1)赫夫曼树(byte数组)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133public class HuffmanByteTree {
//子类 --- 节点
private class Node implements Comparable<Node>{
public int weight;
public Byte b;
public Node left;
public Node right;
public Node(int weight, Byte b) {
this.weight = weight;
this.b = b;
}
public Node(int weight, Byte b, Node left, Node right) {
this(weight, b);
this.left = left;
this.right = right;
}
public int compareTo(Node o) {
return weight - o.weight;
}
public String toString() {
return "Node[weight = " + weight + ", byte = " + b + ']';
}
}
//--------------------------------------------------------------------------------------
private Node root; //根节点
public HuffmanByteTree(byte[] arr) {
createTree(arr);
}
/**
* 创建赫夫曼树
* @param arr 字符数组
*/
private void createTree(byte[] arr) {
List<Node> nodes = toNodeList(arr);
while (nodes.size() > 1) {
Collections.sort(nodes);
Node left = nodes.remove(0);
Node right = nodes.remove(0);
Node parent = new Node(left.weight + right.weight, null, left, right);
nodes.add(parent);
}
root = nodes.get(0);
}
/**
* 将byte数组转成List<Node>
* @param arr 字符数组
* @return List<Node>
*/
private List<Node> toNodeList(byte[] arr) {
Map<Byte, Integer> counts = new HashMap<>(); //字符统计集合(key为字符,value为个数)
//统计字符集合
Integer count;
for (byte b : arr) {
//向Map查询该字符(不存在为null,存在则返回其Integer值)
count = counts.get(b);
if (count == null) {
counts.put(b, 1);
}else {
counts.put(b, count+1);
}
}
//读取Map,并封装为List<Node>集合
List<Node> nodes = new ArrayList<>();
for (Map.Entry<Byte, Integer> entry : counts.entrySet()) {
nodes.add(new Node(entry.getValue(), entry.getKey()));
}
return nodes;
}
/**
* 获取哈夫曼编码
* @return Map<Byte, String>
*/
public Map<Byte, String> getHuffmanCode() {
if (root == null) {
System.out.println("树为空!");
return null;
}
Map<Byte, String> huffmanCodes = new HashMap<>(); //赫夫曼编码集合
StringBuilder route = new StringBuilder(); //路径记录
//递归获取赫夫曼编码,并记录在Map结合中
getCode(huffmanCodes, root, route, "");
return huffmanCodes;
}
/**
* 递归获取赫夫曼编码
* @param huffmanCodes 赫夫曼编码结合
* @param node 节点
* @param route 路径
* @param direction 方向(0为左,1为右)
*/
private void getCode(Map<Byte, String> huffmanCodes, Node node, StringBuilder route, String direction) {
StringBuilder newRoute = new StringBuilder(route); //创建新StringBuilder,避免影响传入的数据(避免影响回溯)
newRoute.append(direction); //拼接路径
if(node != null) {
//判断是否叶子节点
if (node.b == null) {
//向左递归
if (node.left != null) {
getCode(huffmanCodes, node.left, newRoute, "0");
}
//向右递归
if (node.right != null) {
getCode(huffmanCodes, node.right, newRoute, "1");
}
}else {
//是叶子节点,则记录该字节,以及路径(编码)
huffmanCodes.put(node.b, newRoute.toString());
}
}
}
}
- (2)赫夫曼编码压缩与解压
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202public class HuffmanByteCode {
private byte[] metaByte; //原byte数组
private Map<Byte, String> huffmanCodeTable; //赫夫曼编码表
private int lastLen; //数组最后二进制bit长度
//构造器
public HuffmanByteCode(String srcFile) {
//读取文件
metaByte = inputFile(srcFile);
//获取赫夫曼编码表
HuffmanByteTree huffmanByteTree = new HuffmanByteTree(metaByte);
huffmanCodeTable = huffmanByteTree.getHuffmanCode();
}
/**
* 压缩文件
* @param dstFile 压缩文件路径
*/
public void fileZip(String dstFile) {
//将byte数组转成bit字符串
StringBuilder bitStr = new StringBuilder();
for (byte b : metaByte) {
bitStr.append(huffmanCodeTable.get(b));
}
//重新截取bit字符,转成byte数组
//1.计算byte数组长度
int len = 0;
if (bitStr.length() % 8 == 0) {
len = bitStr.length() / 8;
}else {
len = bitStr.length() / 8 + 1;
}
//2.截取bit字符串转成byte数组
byte[] huffmanCodeByte = new byte[len];
int index = 0; //下标
String tempStr = ""; //中间变量
while(index < len) {
int start = index * 8;
int end = start + 8;
if (end > bitStr.length()) {
tempStr = bitStr.substring(start);
}else {
tempStr = bitStr.substring(start, end);
}
huffmanCodeByte[index] = (byte) Integer.parseInt(tempStr, 2);
//记录末尾bit长度
if (index == len-1) {
lastLen = tempStr.length();
}
//index自增
index ++;
}
//输出文件
outputFile(dstFile, huffmanCodeByte);
float zipRate = ((float) metaByte.length - (float) len) / (float) metaByte.length * 100;
System.out.println("压缩成功!");
System.out.println("压缩率为:" + zipRate + '%');
}
/**
* 解压文件
* @param zipFile 压缩文件路径
* @param unzipFile 解压文件路径
*/
public void fileUnzip(String zipFile, String unzipFile) {
//读取数据
byte[] zipByte = inputFile(zipFile);
//将byte数组转成bit类型字符串
String bitStr = bytesToString(zipByte);
//反转码表
Map<String, Byte> alterCodeTable = new HashMap<>();
for (Map.Entry<Byte, String> entry : huffmanCodeTable.entrySet()) {
alterCodeTable.put(entry.getValue(), entry.getKey());
}
//根据反转码表获取原byte数组
List<Byte> unzipByte = new ArrayList<>();
String tempStr = "";
int index = 0;
while (index < bitStr.length()) {
tempStr += bitStr.charAt(index);
if (alterCodeTable.get(tempStr) != null) {
unzipByte.add(alterCodeTable.get(tempStr));
tempStr = "";
}
//index自增
index ++;
}
//将List<Byte>转byte[]
byte[] fileByte = new byte[unzipByte.size()];
index = 0;
for (Byte b : unzipByte) {
fileByte[index] = b;
index ++;
}
//输出文件
outputFile(unzipFile, fileByte);
}
/**
* byte数组转bit字符串
* @param bytes byte数组
* @return String
*/
private String bytesToString(byte[] bytes) {
StringBuilder bitStr = new StringBuilder();
String tempStr;
int temp;
int index = 0; //下标
for (byte b : bytes) {
temp = b;
//补位
temp |= 256;
//截取
tempStr = Integer.toBinaryString(temp);
if (index == bytes.length-1) {
bitStr.append(tempStr.substring(tempStr.length() - lastLen));
}else {
bitStr.append(tempStr.substring(tempStr.length() - 8));
}
}
return bitStr.toString();
}
/**
* 读取文件
* @param srcFile 文件路径
* @return byte[]
*/
private byte[] inputFile(String srcFile) {
FileInputStream fis = null;
byte[] fileByte = new byte[0];
try {
//创建输入流,并读取
fis = new FileInputStream(srcFile);
fileByte = new byte[fis.available()];
fis.read(fileByte);
} catch (Exception e) {
e.printStackTrace();
} finally {
//关闭流
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return fileByte;
}
/**
* 输出文件
* @param dstFile 文件路径
* @param fileByte 数据
*/
private void outputFile(String dstFile, byte[] fileByte){
FileOutputStream fos = null;
try {
//创建流并写入数据
fos = new FileOutputStream(dstFile);
fos.write(fileByte);
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭流
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

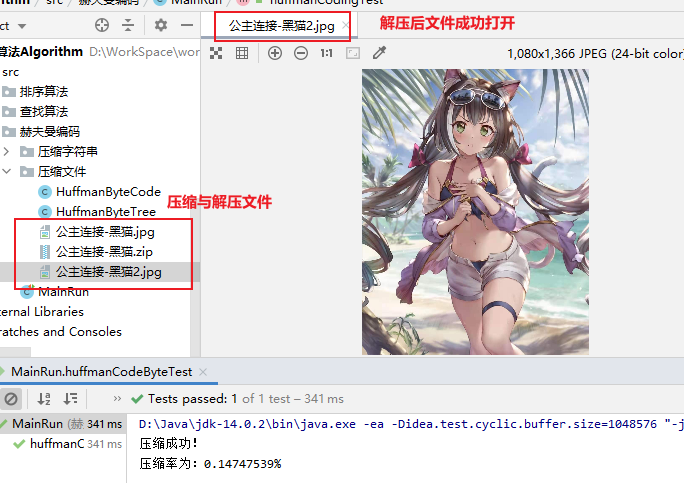
- (3)测试:对上面的图片进行压缩与解压
1
2
3
4
5
6
7
8
9
10
11
12
public void huffmanCodeByteTest() {
String srcFile = "./src/赫夫曼编码/压缩文件/公主连接-黑猫.jpg";
String dstFile = "./src/赫夫曼编码/压缩文件/公主连接-黑猫.zip";
String unzipFile = "./src/赫夫曼编码/压缩文件/公主连接-黑猫2.jpg";
HuffmanByteCode huffmanByteCode = new HuffmanByteCode(srcFile);
//压缩
huffmanByteCode.fileZip(dstFile);
//解压
huffmanByteCode.fileUnzip(dstFile, unzipFile);
}