SQL性能优化:索引,B+树
1 索引
1.1 简介
- 索引是存储引擎用于快速找到数据记录的一种数据结构,类似于书本的目录。
- 创建索引的目的,减少磁盘IO次数,提升查询速率
- 索引的本质:排好序的快速查找数据结构
- 索引是在存储引擎中实现的,存储引擎不同,索引不一定相同(InnoDB中为B+树)
- 每表最大支持16个索引,总索引长度不超256字节
1.2 优缺点
- (1)优点:
- 1、降低数据库IO成本
- 2、唯一索引,保证表中每一行数据的唯一性
- 3、可以加速表与表之间的连接
- 4、减少查询中
分组(grouby by)和排序(order by)的时间
- (2)缺点:
- 1、创建和维护索引耗费时间
- 2、索引占用磁盘空间
- 3、降低更新表的速度
1.3 索引推演
- 以B+树为例,推演出索引的构建 (为了方便理解,构建方式并不是完全正确)
- 基础概念
- 数据:表中的一行数据,称为数据
- 数据页:由多个数据组成,页中数据按照索引字段进行排序,最大16kb
- 目录项:记录数据页中的索引字段的最大值or最小值,方便定位数据页中的数据
1.4 索引分类
1.4.1 聚簇索引
- 聚簇索引:一种数据存储方式,即所有用户记录都存储在叶子节点
【聚簇索引在创建表的时候,会默认根据主键自动进行创建索引】
- 优点:
- 相较于(非聚簇索引),数据访问速度更快
- 对主键的排序查找,范围查找速度更快
- 节省IO操作
- 缺点:
- 插入速度严重依赖于插入顺序(所以尽量让主键为自增)
- 更新主键的代价大
- 限制:
- 聚簇索引只有innodb有,myIsam没有聚簇索引
- 表只有一个聚簇索引,一般为表的主键,若没有主键,则选择非空的唯一索引代替
- 为了充分发挥聚簇索引的特性,建议主键自增
1.4.2 非聚簇索引
- 非聚簇索引(二级索引):以非主键的字段创建的索引,为非聚簇索引。
- 叶子节点保存的数据,不是完整的行数据,而是索引字段和主键字段
- 非叶子节点(目录节点),为了保证数据的唯一性,除了存储索引字段外,也会存储主键字段
- 回表:通过二级索引所查出来的主键字段,回到聚簇索引查找对应的数据,此操作称为回表
1.4.3 联合索引
- 联合索引(属于非聚簇索引):以多个字段来基准创建非聚簇索引
1.4.4 索引区别
- 聚簇索引 与 非聚簇索引 区别
- 聚簇的叶子节点保存的是
数据记录,非聚簇索引保存的是数据位置 - 聚簇索引只有一个,非聚簇索引可以有多个
- 聚簇索引查询效率高,更新表操作比非聚簇索引慢
- 聚簇的叶子节点保存的是
InnoDB B+树索引注意事项
(1)根页面位置万年不变
创建表,添加数据的方式是自上而下的【节点下沉】
(2)内节点中目录项记录的唯一性
内节点(非叶子节点),若节点中索引字段的数据一致,不便于区分,阻碍数据的更新。真实情况是内节点也会保存主键字段进去
(3)一个页面最少存储两条记录
1.5 存储引擎
1.5.1 myisam
- myisam中的索引数据结构为B-树(不是真的B-树,也是一个B+树)
- 与innodb的B+树区别为:叶子节点保存的数据是数据记录的地址
- 因此myisam的索引为”非聚簇索引”
1.5.2 存储引擎区别
- 1、innodb中索引有一个聚簇索引,myisam中索引都基本上是“非聚簇索引”
- 2、innodb中查询主键数据一次查找就能找到对应的记录,myisam无论查什么数据,都会进行回表
- 3、innodb中非聚簇索引叶子节点数据存储的是主键数值,myisam存储的是数据的地址
- 4、myisam回表操作直接通过地址偏移量寻找数据,比innodb中通过主键查找数据速度要快
- 5、innodb要求表必须要有主键,myisam没有要求
1.5.3 优化思路
- 1、innodb不建议使用过长字段作为主键,非聚簇索引会保存主键,过长的主键会令二级索引变得过大
- 2、innodb中,尽量选择单调增的数据作为主键,减少聚簇索引的数据迁移
1.6 索引数据结构对比
1.6.1 hash
- hash:类似Java中的HashMap,有
数组+链表+红黑树组成,对索引字段作为key
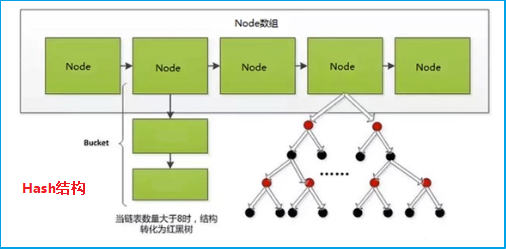
- 优点:
- 等值查找速度快
- 缺点:
- 1、hash索引只支持等于,不等于,In查询;范围查询时,时间复杂度会退化为O(n)
- 2、hash索引数据无序,order by下还要重新排序
- 3、hash联合索引时,将联合索引字段合并,计算出hash值,无法对单独一个键or几个索引进行查询
- 4、索引列重复值很多时,单链表越长,效率会降低
- 限制:
- 1、hash索引支持Memory存储引擎
- 2、innodb不支持hash索引,但提供自适应hash索引(某个数据经常被访问到,就会将这个数据页地址存放到hash表中,当下次查询时,可以直接找到对应的数据页)
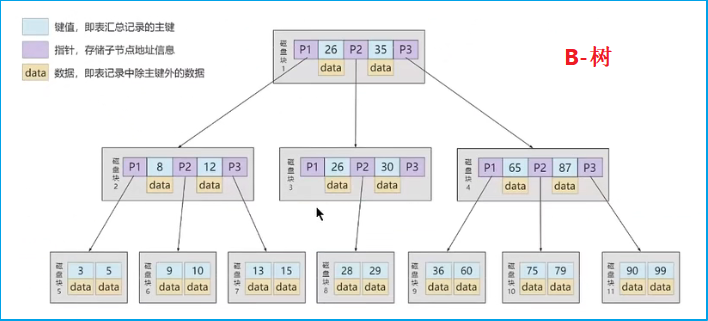
1.6.2 b-tree
- b-tree:是一个
多叉的平衡树。最大的特点就是多叉,以及非叶子节点也会保存数据
2 innodb数据存储结构
2.1 页结构
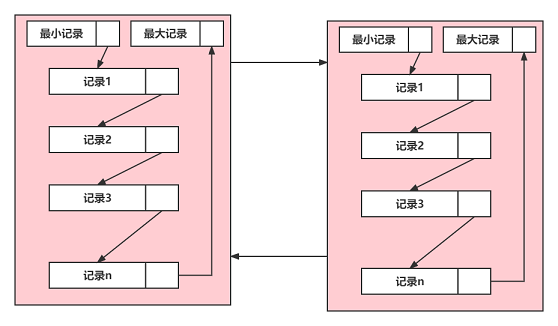
- innodb将数据划分为若干个页,一个页大小16kb(
show variables like '%innodb_page_size%':查看页大小) - 数据库IO操作最小单位为页
- 页中记录以单链表的形式连接
- 页与页之间则是用双链表进行连接
2.2 页上层结构
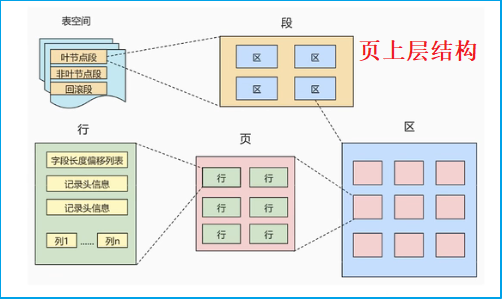
- **区(Extent)**:一个区分配64个连续的页,一个区的大小为1MB
- **段(Segment)**:由一个或多个区组成,段时数据库中的分配单位,不同类型的数据库对象以不同的段形式存在(创建表会有表段,创建索引会有索引段)
- **表空间(Tablespace)**:一个逻辑容器,用于存储段。可以划分为”系统表空间”、”用户表空间”、”撤销表空间”、”临时表空间”等
2.3 页内部结构
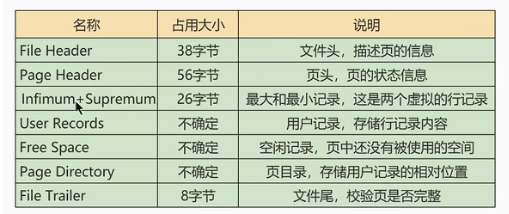
- (1)FileHeader(文件头)
- 描述各种页的通用信息
FIL_PAGE_OFFSET:记录每一个页的单独编号FIL_PAGE_TYPE:记录页的类型,例如索引组成的页,类型为”索引页”FIL_PAGE_PREV:上一页FIL_PAGE_NEXT:下一页FIL_PAGE_SPACE_OR_CHKSUM:校验和,类似hashcode,通过特殊算法计算出来的值,用于判断是否相等FIL_PAGE_SLN:页面最后被修改时对应的日志序列位置
- (2)FileTrailer(文件尾部)
- 校验数据是否完整
FIL_PAGE_SPACE_OR_CHKSUM:校验和,类似hashcode,通过特殊算法计算出来的值,用于判断是否相等FIL_PAGE_SLN:页面最后被修改时对应的日志序列位置
- (3)FreeSpace(空闲空间)
- 每当插入一条数据时,会从空闲空间中划分一条记录大小到UserRecords中
- (4)UserRecords(用户记录)
- 记录按照指定行格式摆放,形成单链表
- (5)Infimum(最小记录)&Supremum(最大记录)
- 记录单链表中数据的最大最小值,用于排序比较
- (6)PageDirectory(页目录)
- 数组形式用于快速查找数据
- 将记录数据进行分组,每组记录最大值数据,形成一个数组
- (7)PageHeader(页面头部)
PAGE_DIRECTION:记录插入的方向PAGE_N_DIRECTION:记录连续N次都插入同一个方式,此值为N
。。。。。。
3 索引创建于设计原则
3.1 索引分类(功能)
- (1)普通索引(normal)
- 不附加任何限制条件,可以创建在任何数据类型上
- (2)唯一性索引(unique)
- 要求索引的字段具有唯一性,但允许字段可以为null值
- (3)主键索引
- 由主键组成的索引,具有唯一性,且字段值不能为null(主键索引只能有一个)
- (4)全文索引(fulltext)
- 利用分词技术等算法,分析出文本中关键词的频率和重要性。查询数据量较大的字符串类型的字段时,全文索引可以提高查询速度
- (5)空间索引
- 空间索引只能简历空间数据类型上(GEOMETRY、POINT、LINSTRING、POLYGON),目前只有myisam支持空间索引,且空间索引字段不能为null
3.2 索引创建
- (1)隐式创建:创建表时,主键约束,唯一约束,外键;都会自动创建索引
- (2)建表时创建索引
1
2
3
4
5
6create table table_name(
字段1,
字段2,
...
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name](colname[length] [ASC | DESC])
);
- (3)创建索引
1
2
3
4
5alter table table_name addd [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name](col_name[length] [ASC | DESC])
# 或
create [UNIQUE | FULLTEXT | SPATIAL] index idx_name on table_name (col_name[length] [ASC | DESC])
3.3 索引删除
1 | alter table table_name drop index idx_name |
3.4 适合创建索引情况
- (1)字段数组有唯一性限制
- 业务上具有唯一特性的字段,即使时组合字段,也必须建成唯一索引
- (2)频繁作为where查询条件的字段
- (3)经常groupBy或orderBy的列
- 多字段优先设置联合索引
- (4)update、delete的where条件列
- (5)distanct字段
- (6)join表的连接条件
- (7)类型小的使用列
- 如:tinyint
- (8)字符串索引使用前缀进行创建
- varchar创建索引时,必须指定索引长度,没必要对全字段创建索引(建议取前20)
- 前缀索引不支持排序,会直接变成文件排序
- (9)区分度高的列作为索引
- 性别之类的不适合索引
- (10)使用最频繁的列放在联合索引的左侧
- 最左匹配
- (11)多个字段创建索引时,联合索引优于单值索引
- 单表创建索引,建议不超过6个
3.5 不适合创建索引的情况
- (1)where使用不到的字段
- (2)数据量少的表
- 例如:目录类(树形结构)
- (3)区分度低的列
- 数据重复度高于10%,不建议添加索引
- (4)频繁更新的字段or表
- (5)字段的值为无序
- 例如:UUID,会经常发生数据转移
- (6)删除不再使用或使用少的索引
- (7)不要定义冗余或重复的索引
4 性能分析
4.1 数据库优化步骤
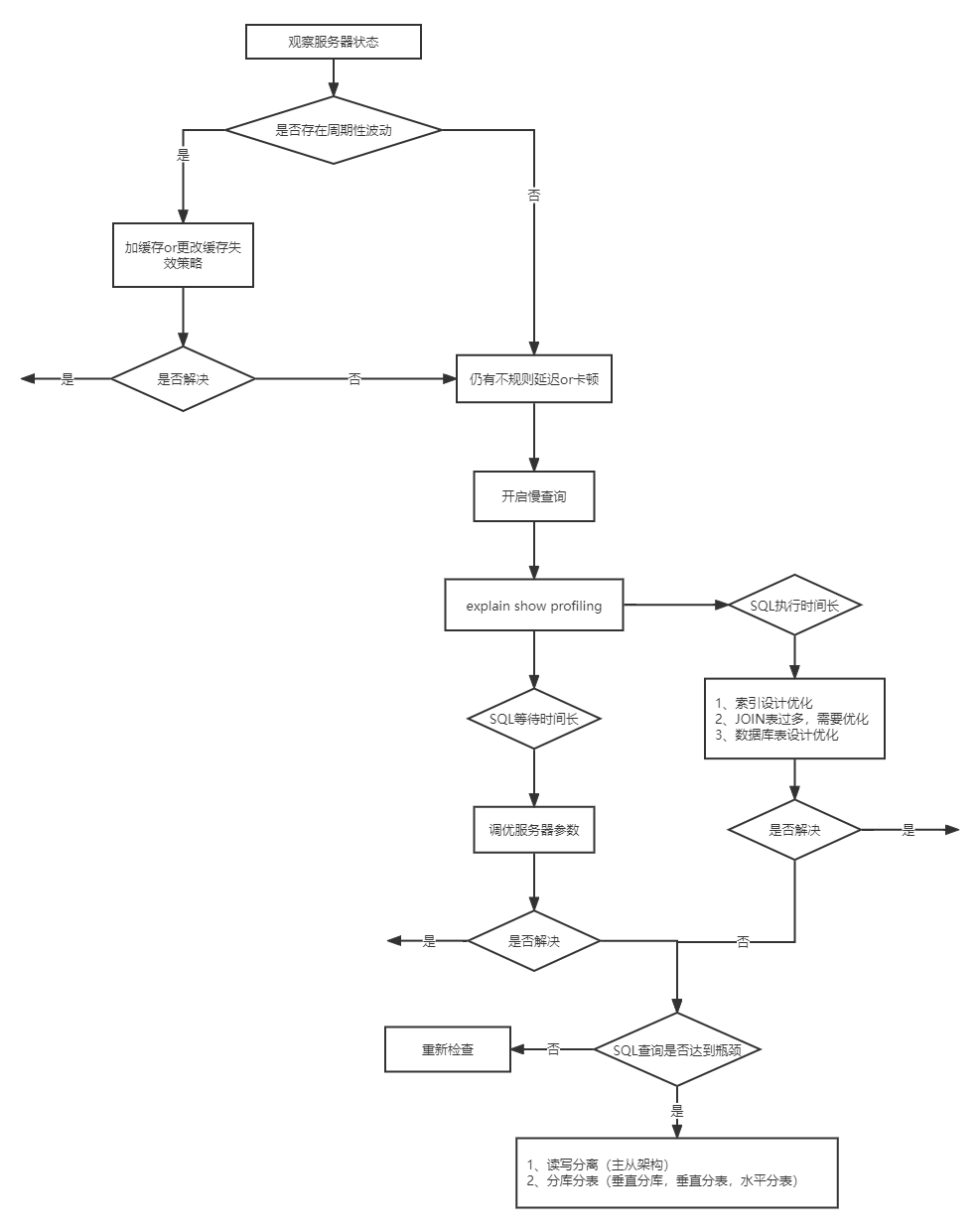
4.2 查看系统性能参数
show status like '参数'
| 参数名 | 含义 |
|---|---|
| Connections | 连接MySQL服务器的次数 |
| Uptime | MySQL服务器上线时间 |
| Slow_queries | 慢查询次数 |
| Innodb_rows_read | select查询返回的行数 |
| Innodb_rows_inserted | 执行insert操作插入的行数 |
| Innodb_rows_updated | 执行update操作更新的行数 |
| Innodb_rows_deleted | 执行delete操作删除的行数 |
| Com_select | 查询操作的次数 |
| Com_update | 更新操作的次数 |
| Com_delete | 删除操作的次数 |
4.3 慢查询日志
- 参数
long_query_time,默认为10,即查询时间超过10s,认为该SQL为慢查询SQL
4.3.1 开启慢查询日志
MySQL默认不开始慢查询日志,因为写日志会影响性能,建议在数据调优时再开启
(1)通过参数配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 查看慢查询日志是否开启
show variables like 'slow_query_log'
# 开启or关闭慢查询日志
set global slow_query_log = [on | off]
# 查看慢查询日志文件位置
show variables like 'slow_query_log_file'
# 查看慢查询阈值
show variables like 'long_query_time'
# 修改慢查询阈值
set global long_query_time = [数值(单位:s)](2)通过配置文件(要重启服务器)
1
2
3
4
5[mysqld]
slow_query_log=ON
slow_query_log_file=/var/lib/mysql/slow.log
long_query_time=3
log_output=FILE
4.3.2 查看慢查询SQL
mysqldumpslow -a -s t -t 5 [日志文件位置]- cmd命令,暂支持linux,window要自行上网查询使用方法
4.4 分析查询语句explain
explain分析支持select、update、delete语句
4.4.1 explain字段
| 字段名 | 含义 |
|---|---|
| id | 唯一id |
| select_type | select关键字对应哪个查询类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配对象的信息 |
| rows | 预估需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| extra | 一些额外信息 |
- (1)type
- 执行查询的访问方法
- System > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > All (越前效率越好)
const:根据主键or唯一索引与常数进行等值匹配eq_ref:join时,被驱动表通过主键or唯一索引进行等值匹配访问ref:普通二级索引与常量进行等值匹配range:使用索引获取某些范围区间的记录index:存在可使用的索引,但需要扫描全部的索引记录all:全表扫描
- (2)Extra
- 更加准确理解MySQL到底如何执行给定的查询语句
No tables used:查询语句没有使用fromImpossible WHERE:where条件永远为falseUsing where:使用全表扫描时No matching min/max row:使用min()或max()聚合函数,但where条件没有匹配上Using index condition:命中索引Using index:命中索引,且为覆盖索引Using join buffer:join时,被驱动表没有索引命中时,会分配join buffer内存快加快查询速度Using filesort:非索引字段进行排序Using temporary:使用临时表,去重情况上常见
4.4.2 explain输出格式
- 传统格式
- JSON格式:
explain format=json [查询语句] - Tree格式:
explain format=tree [查询语句] - 可视化输出:官方SQL工具
5 索引优化与查询优化
- 数据库调优:
- 索引建立
- SQL优化
- 调整my.cnf | my.ini
- 分库分表
5.1 索引失效
- (1)全值匹配
- 当SQL为等值匹配时,创建联合索引,为每一个字段都添加进索引
- (2)最左前缀法则
- 过滤条件使用索引,必须按照索引建立的顺序,依次满足。一旦跳过某个字段,索引的后续字段无法被使用(不一定要按顺序书写,优化器可以重新排序)
- (3)主键插入顺序
- 由于聚簇索引,因此主键自增,能避免索引数据移动
- (4)计算、函数、类型转换导致索引失效
- where的字段使用了计算,函数,类型转换的话,该字段会导致索引失效
- (5)范围条件右边的字段索引失效
- 索引字段A B C,where条件A=1, B>2, C=1,此时索引生效只有A和B,C是范围条件的后边,索引不生效
- (6)不等于条件导致索引失效
- (7)is null 可以使用索引,is not null 不能使用索引
- (8)以通配符%开头,索引失效
- (9)or 前后存在非索引的列,索引失效
- (10)数据库和表的字符集同一使用utf8mb4
- 数据库和表的字符集要统一,不同字符集进行比较会造成索引失效
4.2 查询优化
4.2.1 join优化
- (1)左外连接
- 给on的连接条件创建索引,优先给被驱动表创建索引
- (2)内连接
- 若都有或无索引,小的结果集驱动大的结果集(小表驱动大表)
- 其中一个表有索引,有索引的表作为被驱动表
4.2.2 子查询优化
- 子查询可以通过一个SQL语句实现比较复杂的查询,但执行效率不高
- 子查询会产生临时表,消耗CPU和IO,且临时表无法构建索引
- 优化思路:将子查询改造为join
1 | not in 和 not exists |
4.2.3 排序优化
orderby 中使用索引,避免出现filesort
(1)数据量大时,添加limit xx可以走索引
- 数据量过大时,mysql认为直接全表扫描,比走索引进行回表操作更快
- 索引可以添加limit,让排序可以走索引
- (2)数据量大时,查询字段覆盖索引,会走索引
- 索引创建的字段,刚好时查询的字段,就不会进行回表操作
- (3)排序字段顺序错误,方法相反,都不会走索引
- filesort算法:双路排序和单路排序
- 双路排序(慢):
- 进行两次磁盘扫描;从磁盘取出排序字段,进行排序,排完序后在从磁盘获取其他字段数据
- 单路排序(快):
- 一次性从磁盘中获取所有列的数据,按照指定字段进行排序
- 总结:
- 单路排序虽然效率高,但比较占用内存空间。一旦取出的数据超出
sort_buffer的话,就会创建tmp文件,并多路IO - (1)提高
sort_buffer_sizeshow variables like '%sort_buffer_size%':查看大小
- (2)提高
max_length_for_sort_data- 查询字段的大小超出此值时,会选择双路排序,否则会选择单路排序,尽量不要select *
show variables like '%max_length_for_sort_data%':查看大小
- 单路排序虽然效率高,但比较占用内存空间。一旦取出的数据超出
4.2.4 分组优化
group by 和 order by 基本一致
无法使用索引调高
sort_buffer_size和max_length_for_sort_data
- where 效率高于 having ,能用where过滤就用where过滤
- 尽量减少order by,group by,distinct语句,这些语句都非常耗费CPU;要用也尽量保持在1000行内
4.2.5 分页优化
1 | select * from [table] limit 20000, 10; |
4.3 覆盖索引
- 查询的字段,索引本身就存在,直接在索引中取数据,无需进行回表操作
- 会导致一些不走索引的操作,也会走索引
- 例如:
- (1)数据量大时进行orderby,会进行走索引
- (2)where条件为
!=时,会走索引 - (3)where左模糊匹配,会走索引
- 好处
- (1)避免回表操作,提高效率
- (2)可以把随机IO变成顺序IO,提高效率
4.4 索引条件下推(ICP)
- 索引条件下推(Index Condition Pushdown):数据过滤的优化方法。当where条件的字段在索引中存在时,就算未命中索引(如:左模糊),会直接在索引中进行数据过滤,然后再进行回表,减少回表IO次数
- 好处:减少存储引起访问基表的次数和MySQL服务器访问存储引擎的次数
4.5 其他优化策略
- (1)exist和in区分
- in :
SELECT * FROM A WHERE cc IN (SELECT cc FROM B) - exists :
SELECT * FROM A WHERE cc EXISTS (SELECT cc FROM B WHERE B.cc = A.cc) - 当A表的结果集小于B表时,用exists
- 当A表的结果集小于B表时,用in
- (2)
count(*)与count(具体字段)与count(1)效率 count(*)和count(1)基本上没有区别,效率相等count(具体字段)尽量选择二级索引,加载数据比较少。count(*)和count(1)会自动采用空间最小的二级索引进行统计
- **(3)关于
select *** - mysql解析时,会查数据字典,转换成具体列明,耗费时间
- 无法使用覆盖索引
- (4)limit 1 优化
- 对于全表扫描,limit 1 可以加快查询速度
- 如果对字段建立了唯一索引,无需加上limit 1